
Recently I've noticed something weird happen: I can load websites even when my computer shouldn't be able to connect to the server!
I've finally figured out how this is possible. It turns out it's due to a page speed technique that Google uses on their search result pages.
Blocking the BBC website in /etc/hosts
Contrary to most people's expectations, writing about page speed optimization is not always the most riveting activity. Instead, it drives me to check BBC News 20 times a day.
Thankfully, /etc/hosts comes to the rescue! The hosts file on your computer contains a list of specific domain names and the server IP addresses they should map to.
We can add this line to point www.bbc.co.uk to an IP address without addicting content:
127.0.0.1 www.bbc.co.uk
Instead of ever-changing news reports I now get a nice calming ERR_CONNECTION_REFUSED error.
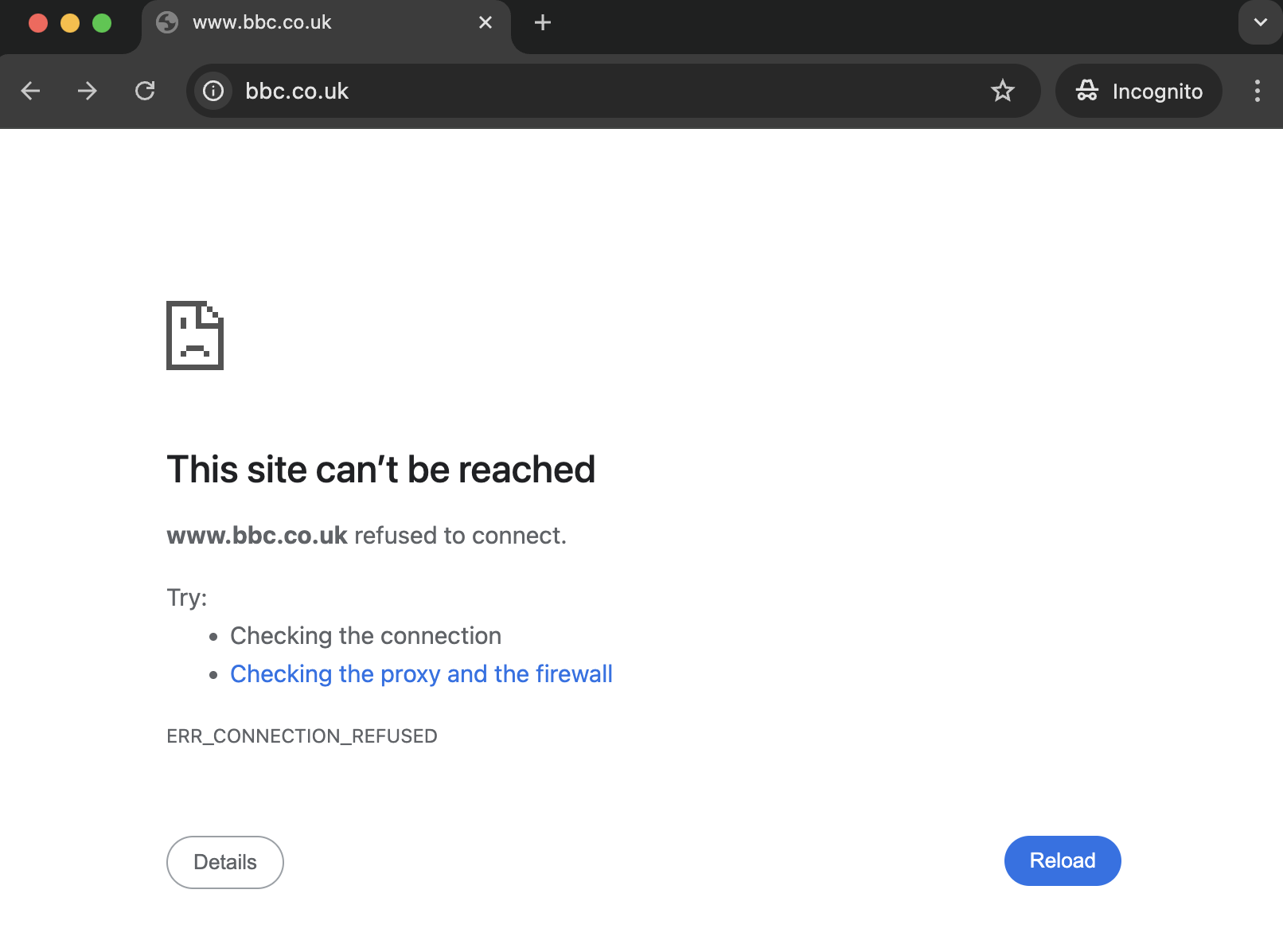
But I can still access the homepage 😮
I usually type "BBC" into a Chrome incognito window when I don't want to work. And when I click the search result link it works just fine?
How am I able to load content from a website that my computer is blocked from accessing???
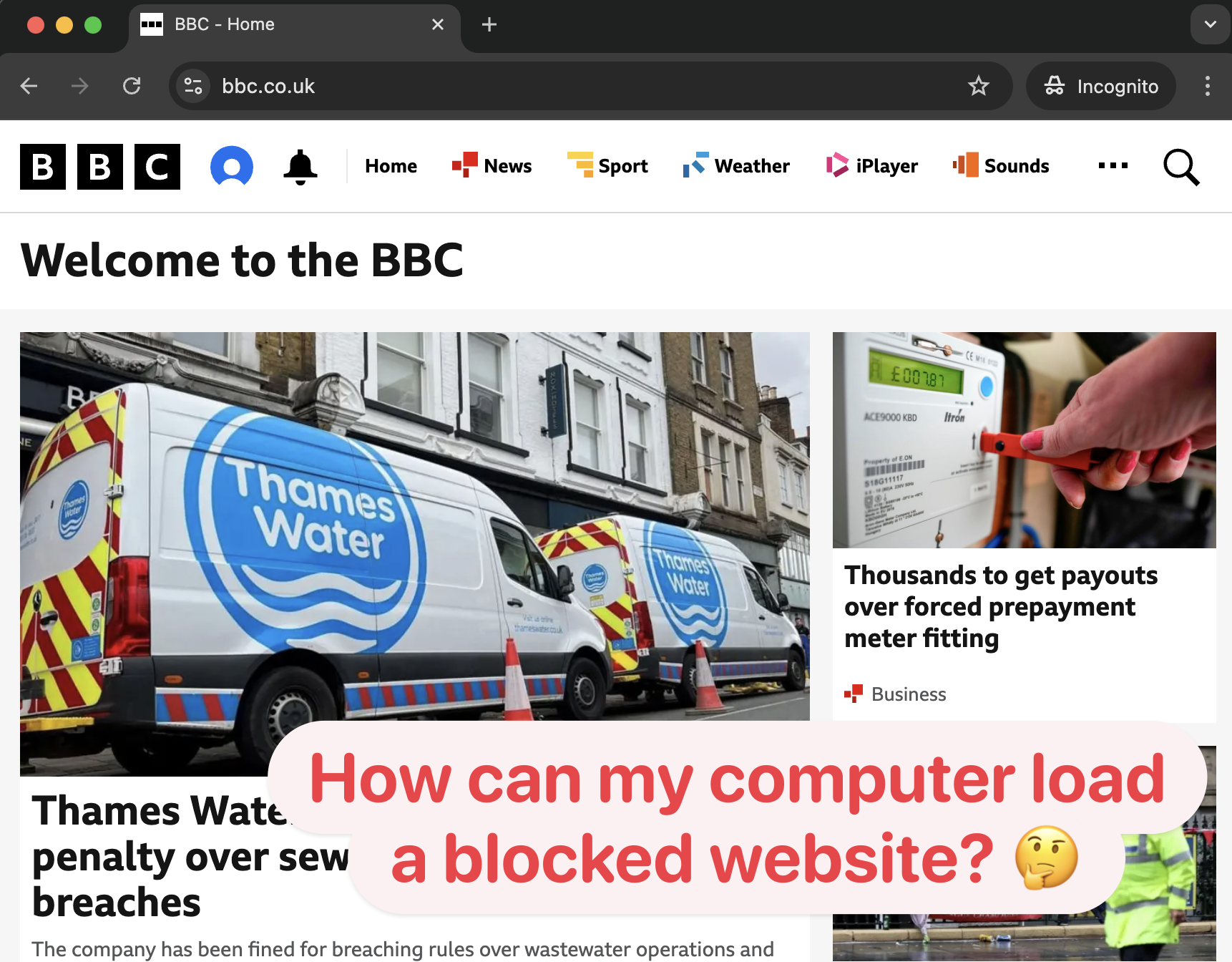
Only when I click through to an article or reload the page do I finally get the error I expected.
Speculation rules and Google proxies
Speculation rules are a way to speed up page navigations in the browser. When a website has speculation rules set up, the browser prefetches or pre-renders content from other pages that the user might visit next.
In particular, Google uses speculation rules to prefetch the HTML document for the first two search results.
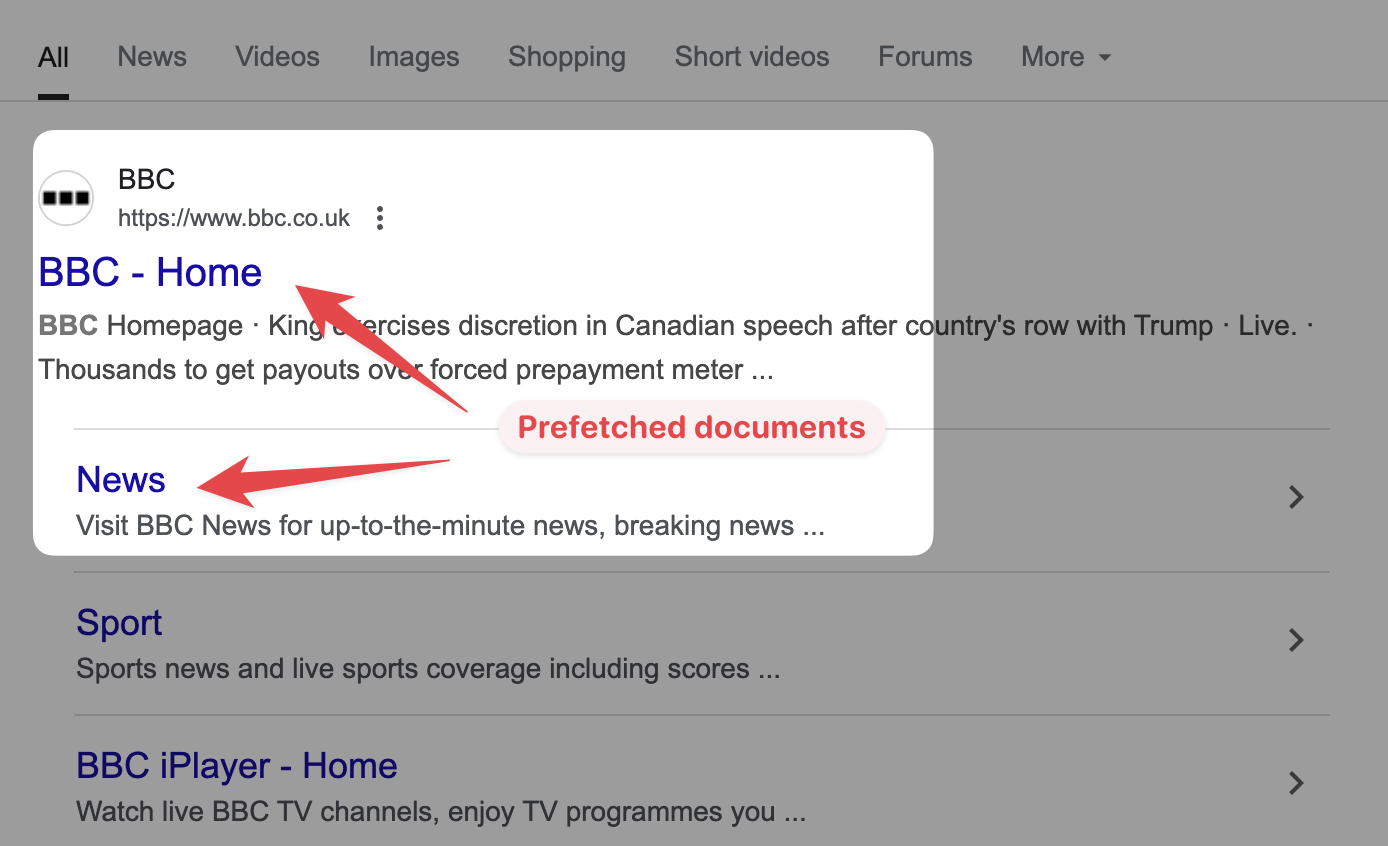
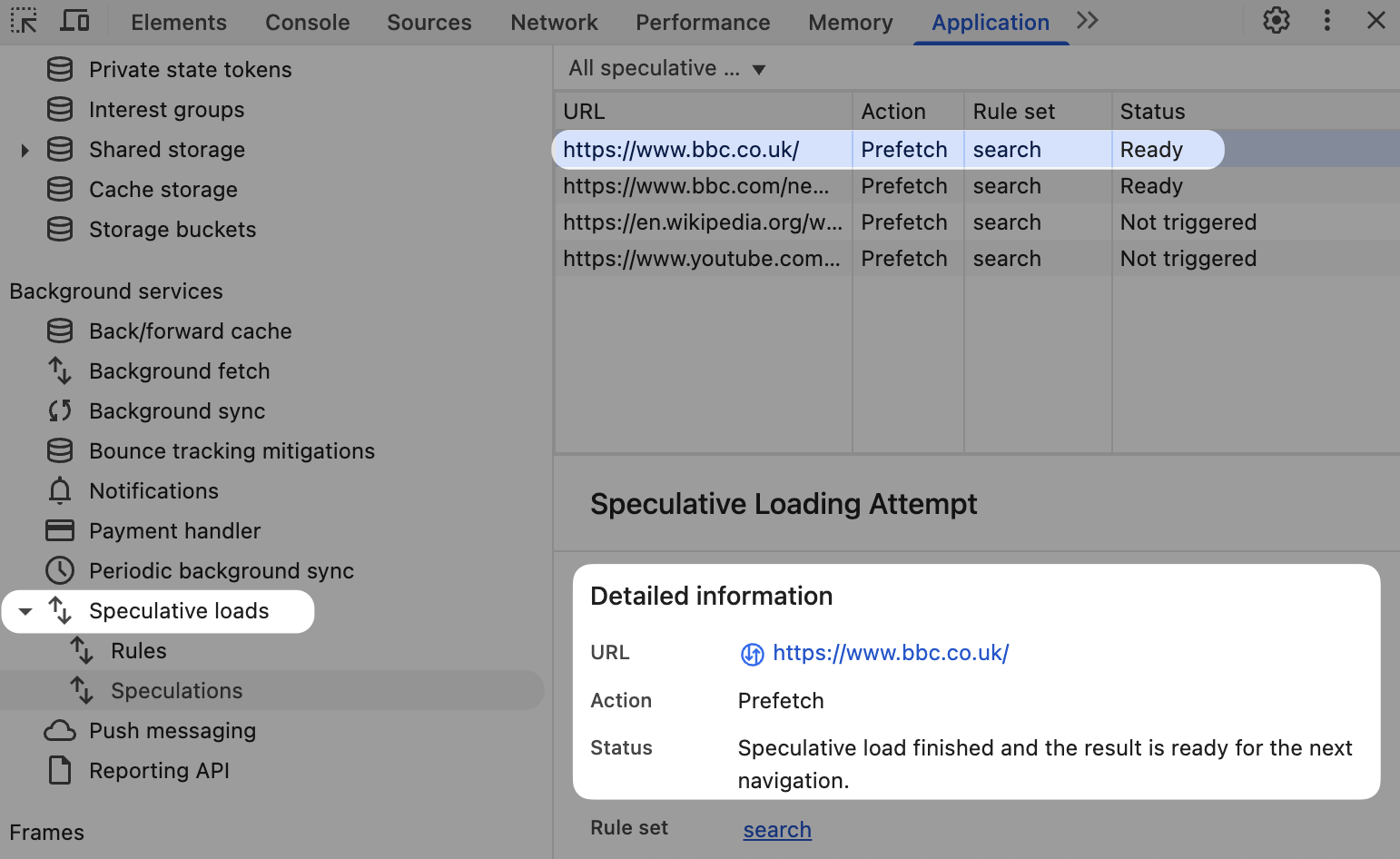
We can confirm that by inspecting the search result page using Chrome DevTools and looking at "Speculative Loads" in the Application tab.
Anonymous client IP
This is the content of the speculation rule from my search result:
{
"prefetch": [
{
"source": "list",
"requires": ["anonymous-client-ip-when-cross-origin"],
"referrer_policy": "strict-origin",
"urls": ["https://www.bbc.co.uk/", "https://www.bbc.com/news/uk"]
}
]
}
Normally, prefetching the website HTML would mean connecting to the website that the document is loaded from. But if Google did that it would be a privacy nightmare, as the user IP would be shared with websites that user never actually visits!
The "requires": ["anonymous-client-ip-when-cross-origin"] property tells the browser that it should only prefetch the resource if it can load the resources using a proxy and without sharing the client IP address.
Currently Chrome only allows Google websites to use this feature, as loading the page through the proxy means the proxy service can access the user IP address and prefetch resource URL.
Chrome users can also enable enhanced preloading in their browser settings to allow proxy prefetches from any website.
So why does the BBC homepage load for me?
Due to the Google proxy I'm able to load the HTML document from a Google server without my computer ever contacting www.bbc.co.uk.
In DevTools we can see that the request was served from the prefetch cache.
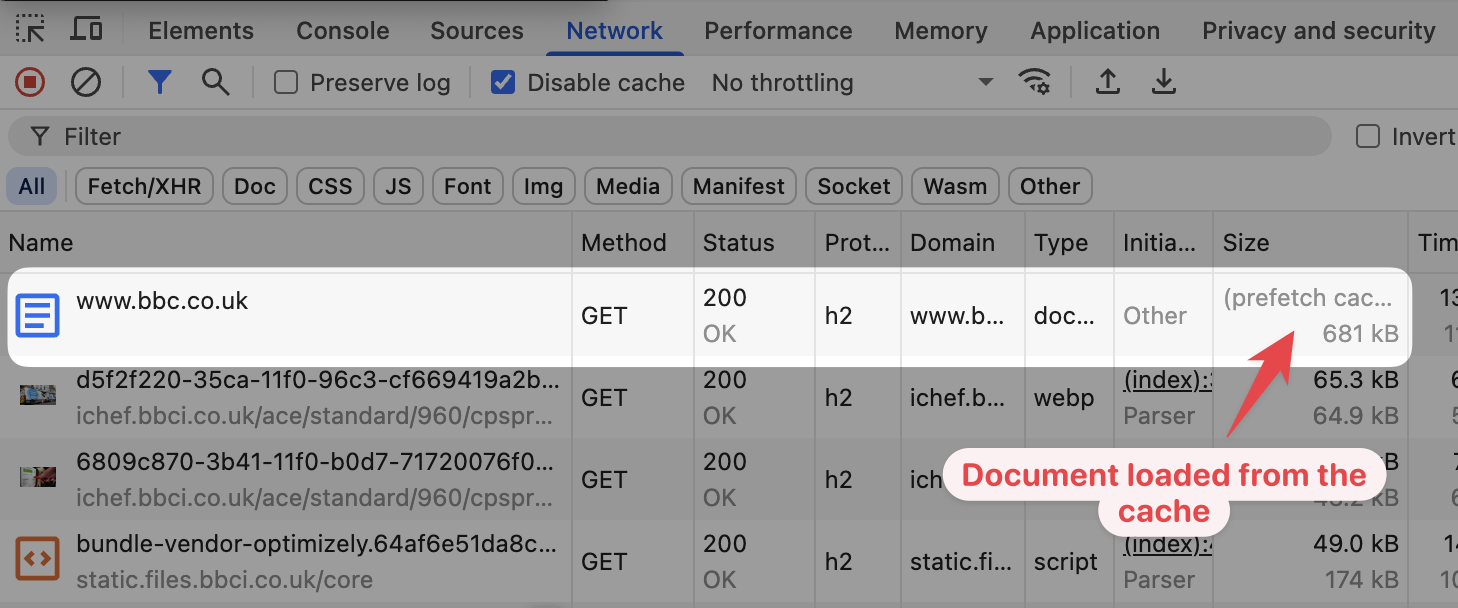
Additional resources like images are served from other domains that are not blocked on my computer, for example ichef.bbci.co.uk.
Why it only works for the first visit
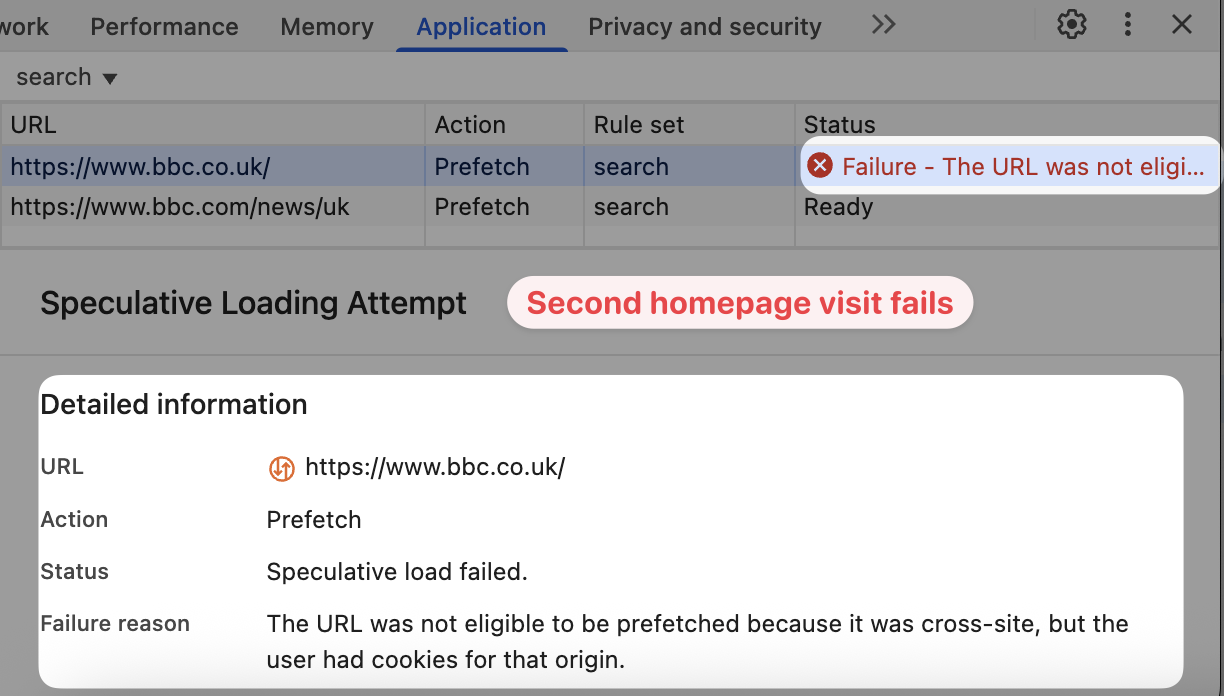
Usually I can only access blocked websites in incognito mode. If I go to a website regularly I get the connection refused error as expected.
That's because the prefetch request isn't made if the user already has cookies set for that domain. When cookies are set page content may be customized for the visitor, so Chrome can't serve the page seen by an anonymous user.
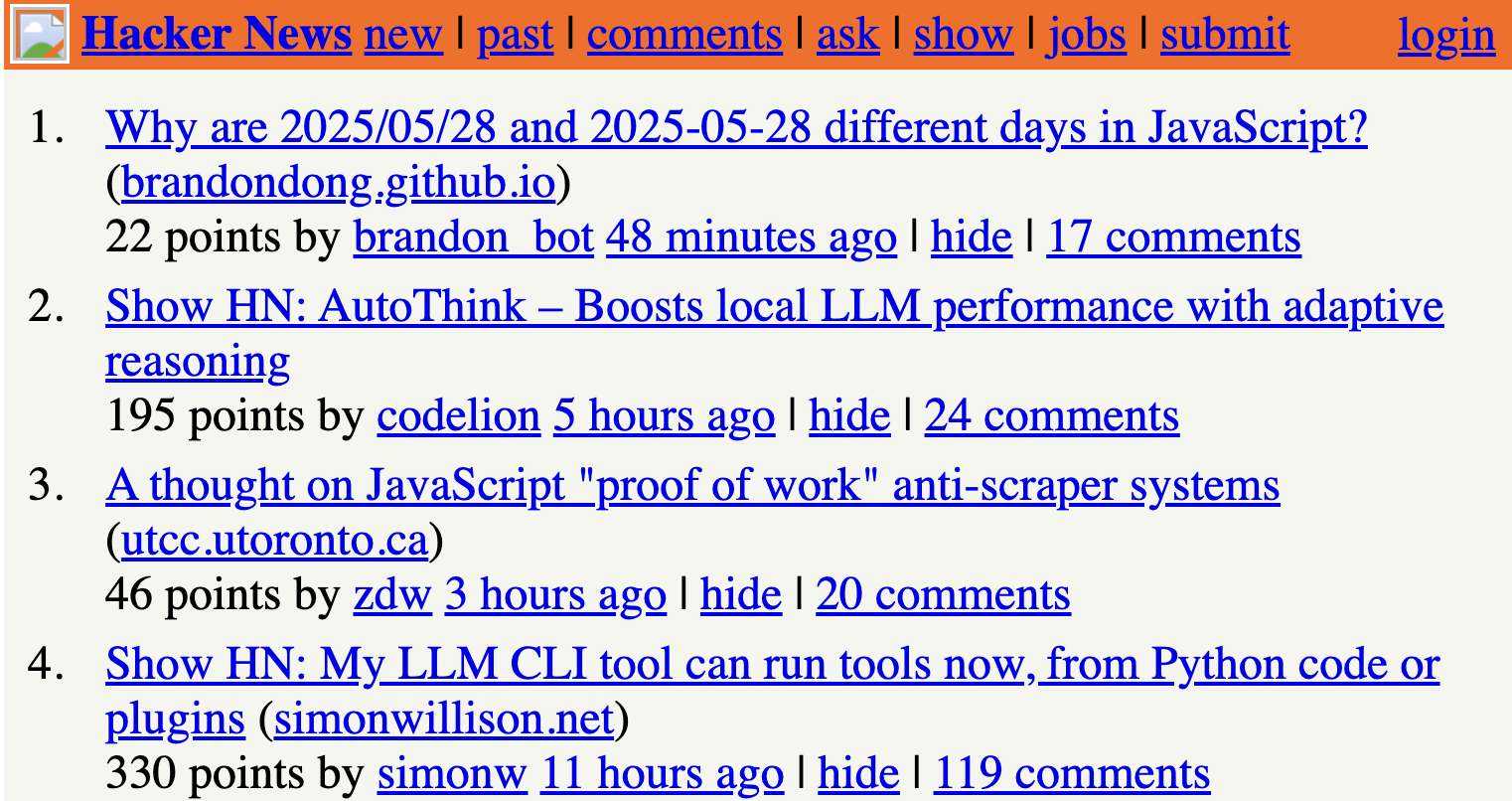
Another example: Hacker News
I also block Hacker News in /etc/hosts. When I type "news.yc" into Google and click on the result the website looks like this:
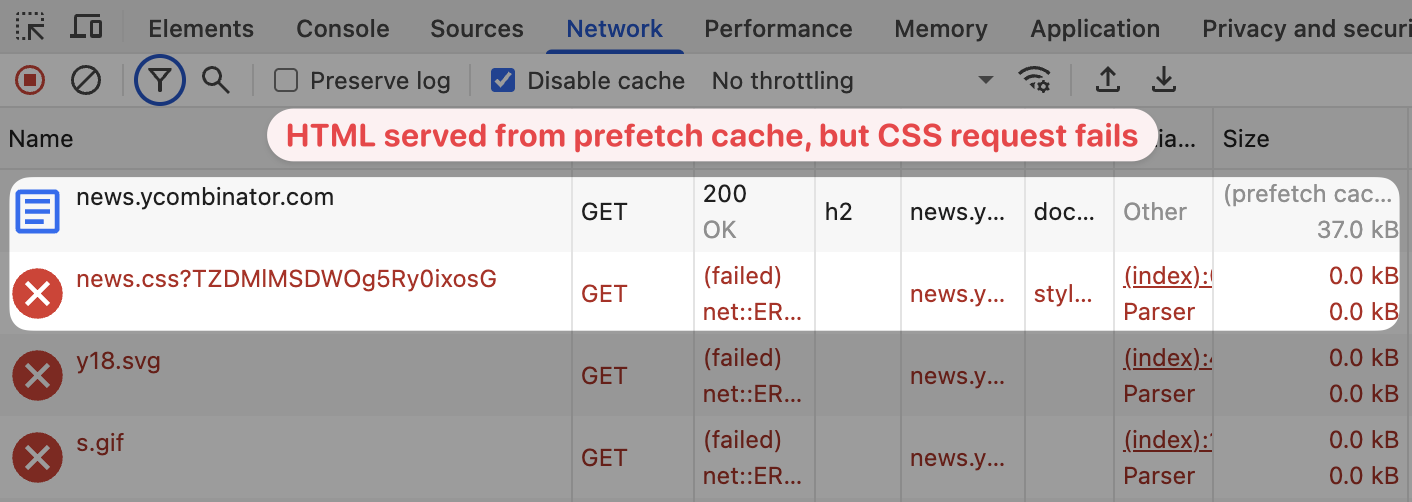
That's because Hacker News loads other resources like stylesheets from the same website domain.
While the HTML document is served from the prefetch cache, loading images and the CSS stylesheet fails because my computer can't connect to the server.
Summary
Google prefetches search result pages using a proxy. Because of that it's possible to load some pages without the computer ever connecting to the website server.
The goal here is to improve page load time. If no other resources are needed to start rendering the page, prefetching the document results in an instant navigation when arriving on the website.
If you're also working on improving your website speed, try out DebugBear for continuous web performance monitoring and analysis.