
What happens when you open a web page in your browser? How is content loaded from the internet and displayed to the user?
This article takes a look at how resources are loaded using the HTTP protocol and how they come together to form a web page. We’ll also take a look at what this means for how long it takes to load a website.
Understanding clients and servers
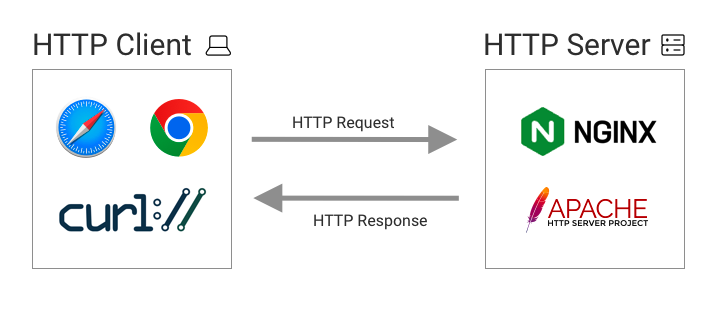
Computers on the internet can act as clients and servers. Clients can request resources from a server on the internet using HTTP requests. The contents of the website are then transmitted to the user. We’ll learn more about the HTTP protocol later on.
Clients are often browsers like Chrome or Safari running on an end user device like a phone or laptop. Mobile apps also use HTTP to load server resources, as do software development tools like curl.
HTTP servers host websites. They receive requests from clients and then return the requested resources. Examples of web servers are NGINX and the Apache HTTP Server.
Resources and Uniform Resource Locators (URLs)
In this context, resources are text files, images, and other media that are loaded over the internet. A web page consists of many different resources. On average about 70 different files are loaded by a page.
When a client requests a resource it needs to specify the name of the resource and what server to request it from. The client also needs to pick a protocol that should be used to make the request.
These bits of information are combined into a web address called a Uniform Resource Locator (URL) like this one: http://example.com/images/photo.jpg?version=2.
We can break this URL down into 5 components:
http://– the protocol that will be used to load the fileexample.com– the domain name. The Domain Name System (DNS) can be used to identify a specific server based on the domain name of the website./images/photo.jpg– the path of the resource. This tells the server what resource you're requesting?version=2– the query string. Usually used to provide additional details about the resource the client is looking for, for example a version number or the resolution of an image

HTTP requests and responses
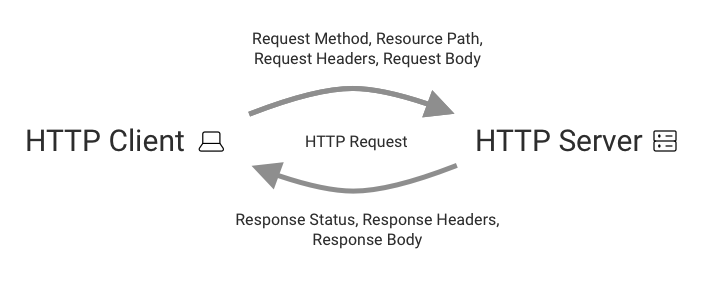
The Hypertext Transfer Protocol (HTTP) provides a way for computers to communicate with each other. It specifies what information clients should provide when making a request and what the server response should look like.
HTTP requests
When making a request, clients need to provide a resource path to specify what resource they are requesting.
Clients can also provide additional information using request headers. For example, a browser could tell the server what image formats it supports so that the server can respond with the best option.
Cookies are also included in the HTTP headers, for example to identify a logged-in user. When two different people go to the Twitter homepage the server can respond with a different timeline for each one.
The client also provides a method, saying what the browser wants to do with the resource. When loading a website the method is usually “GET” which means that the browser wants to download the resource. When submitting data to a website the “POST” method might be used instead.
HTTP requests can also contain a body. A body is not provided when downloading a resource, but for example when uploading a file it would contain the contents of the file.
Simplified example
A basic HTTP request could look like this:
GET /photo HTTP/1.1
Host: example.com
User-Agent: Intel Mac OS, Chrome/109.0.0.0
Accept: image/avif,image/webp,image/apng,image/svg+xml
The Host header tells the server what website we want to load the resource from. A single web server can be used to host multiple websites, so the Host header is needed to distinguish them.
The User-Agent header tells the server about the application that's making the request on behalf of the user. In this example that's Chrome on Mac OS.
By providing the Accept the server knows what kind of response the user agent can handle, for example whether the WebP image format is supported.
HTTP responses
An HTTP response consists of three parts: a status code, response headers, and the response body.
The status code indicates whether the request was successful. For example, a 200 OK status indicates that everything went fine. A 404 Not Found status shows that the requested resource doesn't exist on the server. If the server ran into an error while trying to process the request it will return a 500 Internal Server Error status.
Response headers provide additional information about the response. For example, is the file type PNG or JPG? If the browser needs to load the same resource tomorrow, should it make a new request or just use the old response again?
Finally, the response body contains the actual content of the resource.
Try our free HTTP header checker to view the HTTP status code and response headers for any website.
Example of an HTTP request and response
Let’s use the curl command line tool to make an HTTP request. Alternatively you can take a look at requests in Chrome DevTools.
curl -X GET -i http://example.com
We pass in the resource we want to load and the -i flag tells curl that we want to view the full response data, including the status code, headers, and response body. The -X flag lets us specify the request method.
Here are the first 18 lines of the server response:
HTTP/1.1 200 OK
Accept-Ranges: bytes
Age: 343787
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Mon, 16 Jan 2023 11:16:47 GMT
Etag: "3147526947"
Expires: Mon, 23 Jan 2023 11:16:47 GMT
Last-Modified: Thu, 17 Oct 2019 07:18:26 GMT
Server: ECS (nyb/1D1E)
Vary: Accept-Encoding
X-Cache: HIT
Content-Length: 1256
<!doctype html>
<html>
<head>
<title>Example Domain</title>
That’s a lot of information! We can see that our request was successful (200 OK status code) and that version 1.1 of the HTTP protocol was used.
There are 12 response headers in total, mostly to control caching behavior or to provide additional information about the response.
The value of the Content-Type header is text/html. That indicates that the response is an HTML document, the language that browsers use to display websites.
You can recognize HTML code based on the text in angle brackets. These are called tags and we can see html, head, and title tags in the first few lines of the document above.
The HTML document provides the page content and overall structure of the page. Based on this information the browser then renders the website.
For example, we can see this snippet <title>Example Domain</title> in the HTML response. Chrome uses this information as the title of the browser tab.
Combining resources into web pages
Websites rarely require just one request to load. The HTML language provides options to reference additional resources, for example images:
<img src=”/images/photo.jpg”>
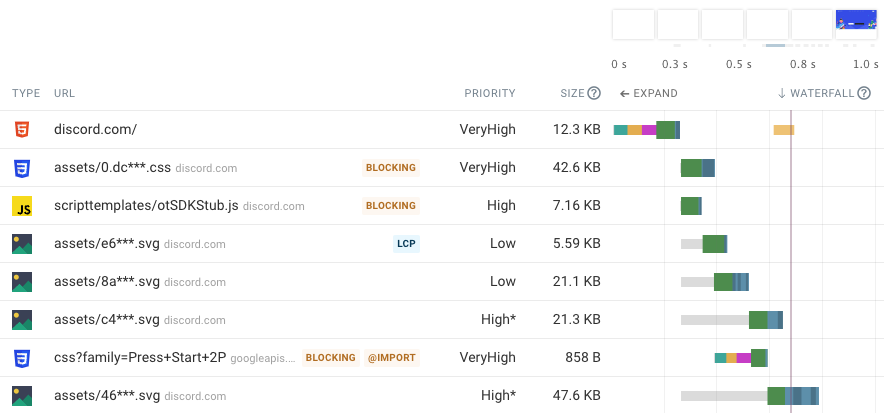
A request waterfall can show all the resources that are loaded by a website. Many websites consist of over a hundred different resources.
We can see four types of resources in the request waterfall below:
- An HTML document containing the content and structure of the website
- A CSS stylesheet that says how the page content should be displayed, for example text sizes or where on the page content should be shown
- A JavaScript file that contains code that’s run on the page, for example to modify page content after the initial load
- Images that are displayed on the page
Some resources, such as JavaScript application code, can themselves request other resources. Here’s an example of an HTML file that loads a JavaScript file, which in turn loads another JavaScript file, which then loads an image.
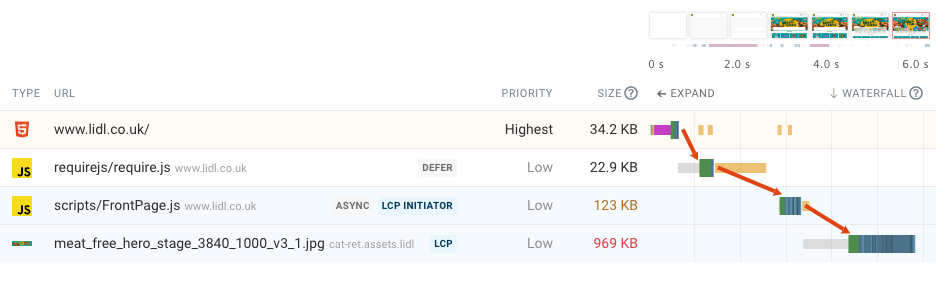
Rendering the page
Once the page has loaded the most important resources it can start rendering it. That means taking the HTML and CSS code and turning it into the website that the user can see on the screen.
At a high level the browser needs to do this to render a page:
- Read the HTML code to identify UI elements
- Find the CSS styling rules that are applicable to each UI element
- Calculate the layout of the page, meaning where on the page each UI element should go and how large it will be
- Paint the page elements, turning the abstract structure of the web page into pixels on the screen
You can read more about how rendering works here.
Server connections
So far we’ve talked about the simple request/response model of HTTP. But how does the client find the server it needs to talk to? How can client and server exchange data without revealing it to other computers on the internet? What happens when the client data gets lost on the way?
Computers use secure server connections to achieve this. We've written another article that goes into depth on what server connections do and what's involved in connecting to an HTTP server.
When looking at a request waterfall you can see that before making an HTTP request the browser first needs to establish a connection to the server. The connection can be reused when loading more resources from the same server later on.
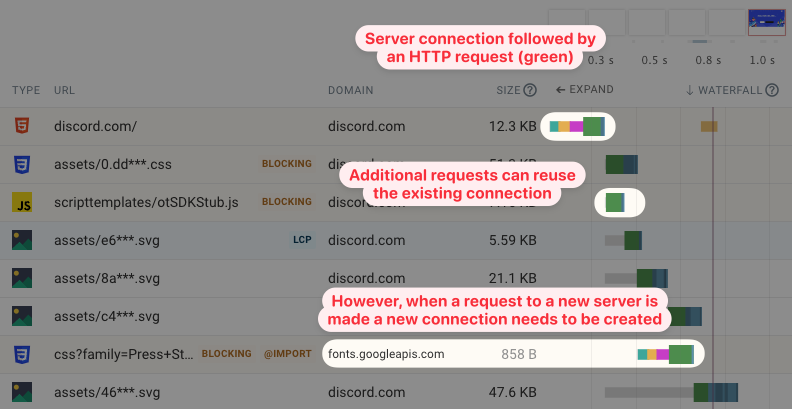
However, when a resource from a different server is needed then a new connection needs to be created. In this example the Discord website loads a CSS stylesheet file from fonts.googleapis.com. So the browser needs to create a new server connection.
What does this mean for website speed?
Since websites are made up of many different resources their content often shows up gradually over the course of a few seconds as requests for those resources are made.
For example, here the page remains blank for the first 0.7 seconds. Then the content at the top of the page shows up. Then after over 4 seconds the bottom of the page renders.
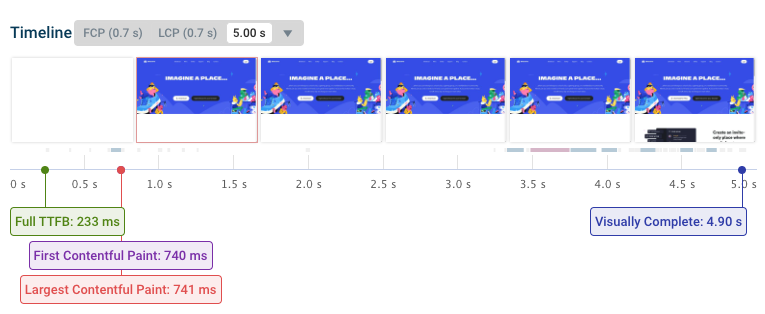
This visualization is called a filmstrip view. The markers below the filmstrip highlight page rendering milestones. For example, the Largest Contentful Paint metric measures how soon after opening the page the biggest text or image element shows up.
All resources on a page also aren’t equally important for page speed. Without the HTML document no content can be shown. But an image way down in the website footer can load after the page has rendered and the user can see the page contents.
CSS stylesheet resources are also often render-blocking. Viewing only the raw HTML content without styling would not be helpful to the user.
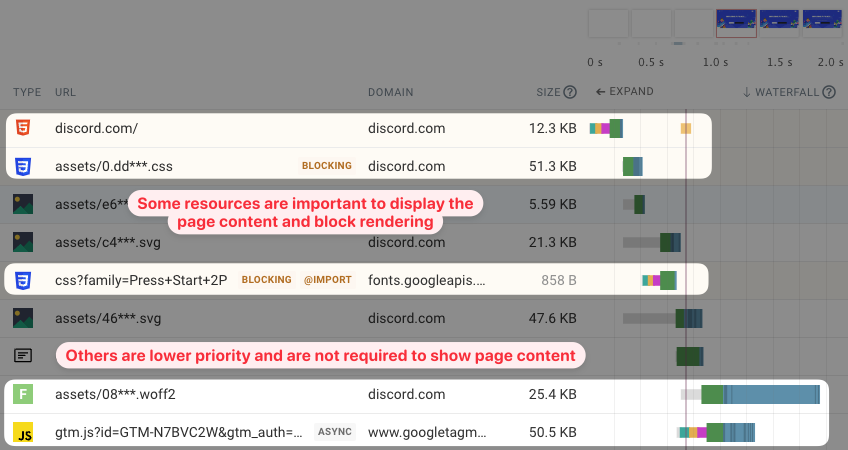
The waterfall above shows two render-blocking CSS stylesheets. But we can also see that, after the page has rendered, the browser loads a Woff2 font file and a JavaScript application. These last two files don’t block rendering and are less important for page performance.
A website will be faster if it loads fewer resources, the most important resources are loaded first, and the resources are as small as possible. You can run a website speed test to see what resources a website loads and how long it takes to load a page.
Websites that load quickly not only benefit visitors but also rank higher in Google and have other business benefits.
Learn more
To learn more about how websites work you can learn the basics of web development.
Looking at websites in Chrome DevTools is also a great way to find out more about how a website is structured and what resources it consists of.